Cross-Entropy Loss là gì?
This post reviews some extremely remarkable results in applying deep neural networks to natural language processing (NLP)
Contents
- Contents
- Introduction
- Entropy
- Cross Entropy
- KL Divergence - KL phân kỳ
- Khả năng dự đoán
- Likelihood
- Thảo luận
- Nguồn tham khảo
Introduction

Mục tiêu của bài toán phân lớp dựa trên tính toán xác suất (Probabilistic classification) là gán (map) dữ liệu đầu vào cho nhãn của lớp có xác suất cao nhất, và chúng ta thường train mô hình bằng điều chỉnh tham số của mô hình sao cho xác suất dự đoán được càng sát với ground-truth probabilities càng tốt.
Chúng ta giả sử chỉ xét mô hình với nhãn các lớp là phân biệt. Ví dụ cho bài toán phân lớp ảnh số từ MNIST database với input là danh sách các ảnh và output là số từ , mô hình sẽ dự đoán xác suất output (cho mỗi ảnh input tương ứng) là danh sách số mỗi số là xác suất mà ảnh đầu vào sẽ thuộc lớp tương ứng, và thoả mãn:
Trong quá trình training, giả sử chúng ta có ảnh input là ảnh mang số và mô hình được kỳ vọng sẽ dự đoán xác suất đầu ra gần với ground-truth class probability , nghĩa là xác suất tại vị trí số của output đạt . Giả sử mô hình dự đoán phân bố xác suất output khác biệt so với target , với , thì chúng ta sẽ phải điều chỉnh tham số của mô hình sao cho tiến gần tới .
Vậy thế nào là điều chỉnh tham số cho tiến gần tới . Ở đây nghĩa là chúng ta sẽ tìm cách đánh giá sự khác biệt giữa và .
Có nhiều cách để đánh giá sự khác biệt này, ở post này chúng ta sẽ đi tìm hiểu một trong số những cách phổ biến nhất đó chính là cross-entropy, và đánh giá tại sao cross-entropy lại phù hợp cho bài toán phân lớp (classification).
Entropy
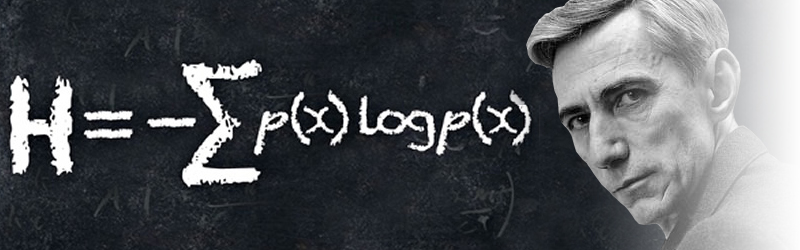
Code, Codeword, Encode-Decode
Các bạn hẳn vẫn còn nhớ cô nàng Alice và anh chàng Bob trong những câu chuyện về an toàn bảo mật thông tin. Lần này câu chuyện của 2 bạn ấy như sau: Bob rất thích động vật, anh ấy có thể nói chuyện cả ngày với Alice về chủ đề động vật. Đặc biệt khi nói chuyện với Alice anh ấy luôn chỉ có nói 4 từ: “dog”, “cat”, “fish” và “bird”.
Một lần Bob đi du lịch xa, Bob liên lạc với Alice qua tin nhắn và mã hoá tin nhắn chỉ gồm các ký tự nhị phân và . Tin nhắn của Bob như sau:

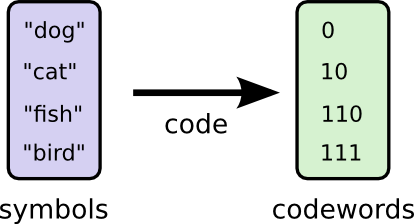
Để thuận tiện cho việc trao đổi, Bob và Alice cùng thống nhất với nhau về cách thức mã hoá tin nhắn bằng cách thay thế từng từ thành chuỗi nhị phân (codeword) độ dài 2 bit tương ứng và ghép lại thành 1 chuỗi tin nhắn duy nhất. Cụ thể:
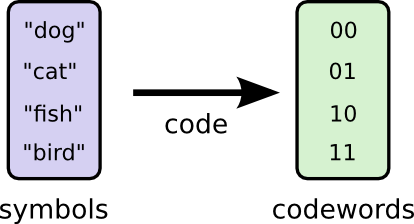
và giải mã thông tin như sau:
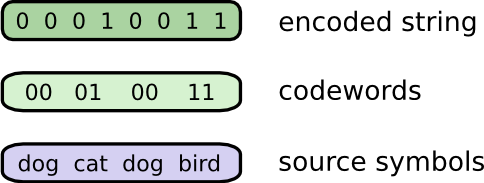
Mọi chuyện sẽ không đáng lo nếu như giá cước là đồng/1 bit, nhưng nay đã tăng lên là đồng/1 bit. Giá cả đắt đỏ chẳng nhẽ lại thôi không liên lạc nữa. Do vậy, Bob và Alice quyết tìm ra cách nào đó để tin nhắn ngắn hơn (để giảm cước phí) nhưng vẫn đảm bảo chuyển tải được đầy đủ thông tin.
Cùng nhau xem xét lại lịch sử các tin nhắn, Alice thấy rằng Bob tần suất các từ trong tin nhắn của Bob không tương đương với nhau. Cụ thể là: Bob thực sự thích “dog”, anh ấy chủ yếu nói về “dog” trong mọi tin nhắn của mình, thỉnh thoảng Bob mới nhắc đến 3 con vật còn lại là “cat”, “fish” và “bird”. Tần suất cụ thể như bảng thống kê dưới đây:
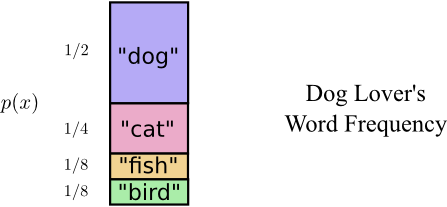
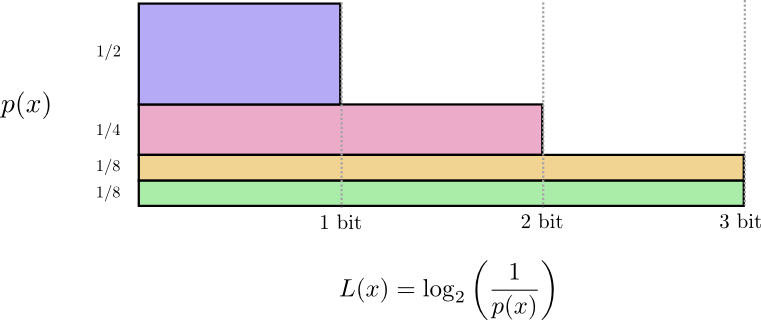
Phân tích một cách chi tiết hơn về codeword mà 2 bạn đã dùng bằng biểu đồ dưới đây, với: Trục tung - Thể hiện xác suất xuất hiện của 1 word; Trục hoành - Độ dài của codeword tương ứng; Diện tích - Expected codeword lenght: Độ dài kỳ vọng hay độ dài trung bình của một codeword được gửi đi, ở đây = 2 bit:
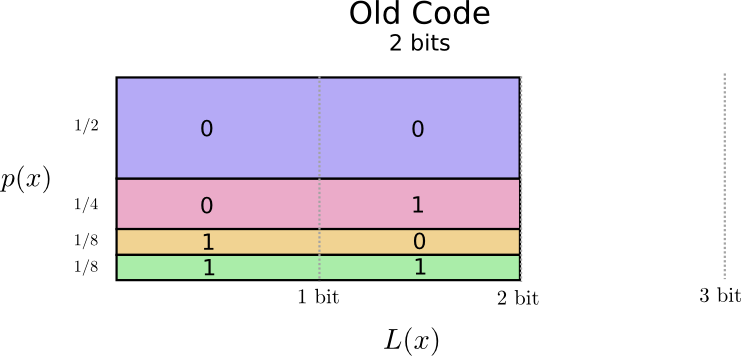
Như vậy, mục tiêu của 2 bạn là cực tiểu độ dài của tin nhắn gửi đi. Ở đây là hoàn toàn có thể lựa chọn codeword có độ dài khác nhau. Theo thuật toán tham lam thì word nào xuất hiện nhiều (word phổ biến, ví dụ như “dog”) sẽ ưu tiên chọn độ dài codeword tương ứng ngắn hơn và ngược lại những word nào xuất hiện ít (word hiếm, ví dụ như “bird”) thì codeword sử dụng sẽ dài hơn. Cụ thể ta có được như sau:
Biểu đồ phân tích cho bộ codeword mới như sau:
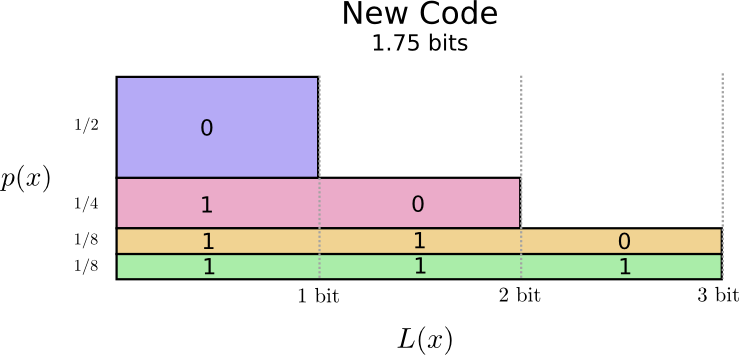
Để ý rằng trong biểu đồ trên độ dài của codeword phổ biến ngắn hơn trong khi đó độ dài của codeword hiếm là dài hơn. Phần diện tích được tính toán cũng nhỏ hơn,và tương ứng với độ dài trung bình của codeword là . Như vậy bằng cách sử dụng codeword có độ dài khác nhau ta có thể làm cho độ dài trung bình của codeword nhỏ hơn.
Bạn cũng có thể tự hỏi rằng tại sao ko dùng tất cả codeword độ dài bằng 1 cả. Với cách này thì bạn sẽ gặp phải vấn đề nhập nhằng (ambiguity) trong quá trình giải mã (decode)(sẽ giải thích cụ thể hơn ở phần tiếp).
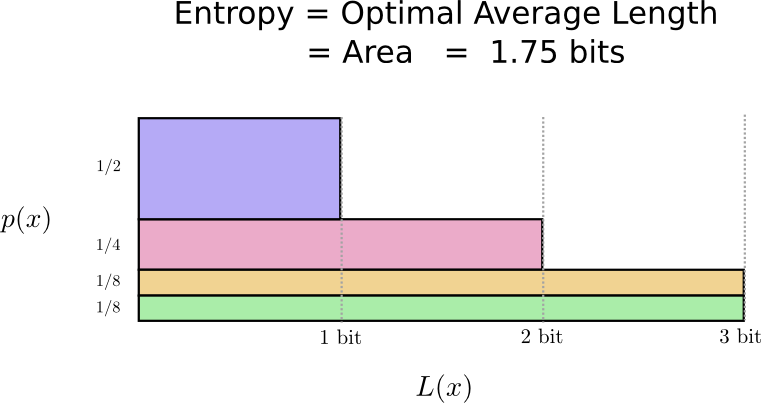
Với ví dụ trên cùng với phân bố xác suất , thì là giá trị tối ưu, nghĩa là chúng ta sẽ không tìm được bộ codeword nào phù hợp mà có giá trị trung bình nhỏ hơn .
Như vậy, các bạn có thể thấy rằng với mỗi bộ phân bố xác suất cho trước, ta hoàn toàn xác định được giá trị tối ưu của code, hay độ dài trung bình tối ưu của codeword. Và giá trị này được gọi là Entropy.
Không gian codeword
Chúng ta có 2 codeword độ dài 1 là: 0 và 1; 4 codeword độ dài 2 là: 00, 01, 10, 11; và tổng quát là codeword độ dài n.
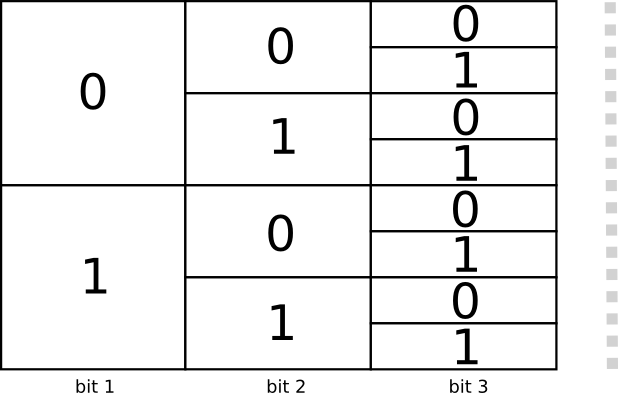
Như trên đã nói, bạn hoàn toàn có thể tuỳ ý lựa chọn codeword có độ dài bất kỳ. Ví dụ như hình trên là 8 codeword độ dài 3, bạn có thể lựa chọn một cách tổ hợp các codeword có độ dài khác nhau như bạn chọn 2 codeword độ dài 2, 4 codeword độ dài 3 chẳng hạn.
Vậy điều gì quyết định đến việc chọn lựa codeword với độ dài khác nhau.
Ở hình dưới, Bob mã hoá tin nhắn bằng cách thay thế từng word bằng codeword tương ứng và ghép lại thành một chuỗi mã hoá nhị phân.
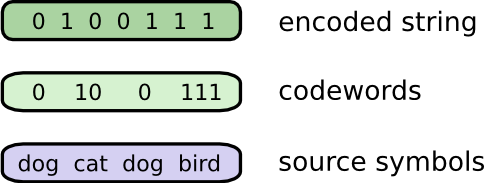
Có một điều bạn cần lưu ý ở đây là làm thế nào để từ chuỗi mã hoá bạn có thể giải mã ngược lại thành chuỗi các codeword. Nếu như chọn codeword có độ dài như nhau thì việc này khá đơn giản. Tuy nhiên bạn lựa chọn codeword độ dài khác nhau việc giải mã ngược lại được thành chuỗi codeword là việc hết sức quan trọng.
Thực tế, bạn cần chọn bộ codeword sao cho việc giải mã là duy nhất. Bằng không bạn sẽ rơi vào tình trạng “nhập nhằng”, nghĩa là từ một chuỗi mã hoá sẽ có nhiều chuỗi giải mã thoả mãn. Ví dụ, nếu bạn chọn cả và trong bộ codeword của bạn, thì với chuỗi mã hoá bạn sẽ khó quyết định đâu là codeword phù hợp được dùng để giải mã cho 2 bit đầu. Do đó, bạn sẽ không chọn bộ codeword là prefix code - nghĩa là không codeword nào là prefix của codeword trong cùng một bộ.
Để dễ dàng cho việc lựa chọn prefix code, bạn sẽ sử dụng một phương pháp gọi là “hi sinh”, nghĩa là khi bạn đã chọn một codeword, ví dụ như , thì toàn bộ không gian codeword bắt đầu bằng sẽ không được sử dụng, ví dụ bạn sẽ không được dùng các codeword như: , , … bởi nó sẽ gây ra tình trạng “nhập nhằng” cho quá trình giải mã.
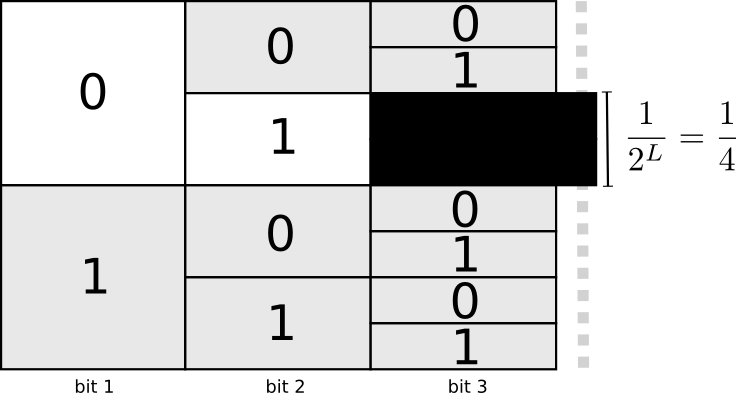
Với trong tổng số codeword bắt đầu bằng , như vậy nếu codeword được chọn, bạn sẽ phải “hi sinh” tổng số codeword. Đây là “chi phí” bạn phải trả để có được một codeword độ dài 2.
Optimal Encoding - Mã tối ưu
Ở đây, bạn coi việc này giống như bạn đang có một ngân khố đầy đủ với tỷ lệ , mỗi khi bạn chọn một codeword độ dài L thì theo thuyết “hi sinh” ở trên bạn phải “hi sinh” một “chi phí” với tỷ lệ codeword là .
Chi phí cho codeword có độ dài là - tức toàn bộ codeword - nghĩa là nếu bạn chọn codeword có độ dài 0 thì bạn sẽ không được chọn bất kỳ codeword nào khác nữa; Chi phí cho codeword độ dài 1, ví dụ như codeword , là vì có số lượng codeword bắt đầu bằng ; Chi phí cho codeword độ dài 2, ví dụ “”, là vì có số lượng codewprd bắt đầu bằng “10”. Tổng quát, Chi phí cho codeword giảm theo hàm luỹ mũ của độ dài codeword.
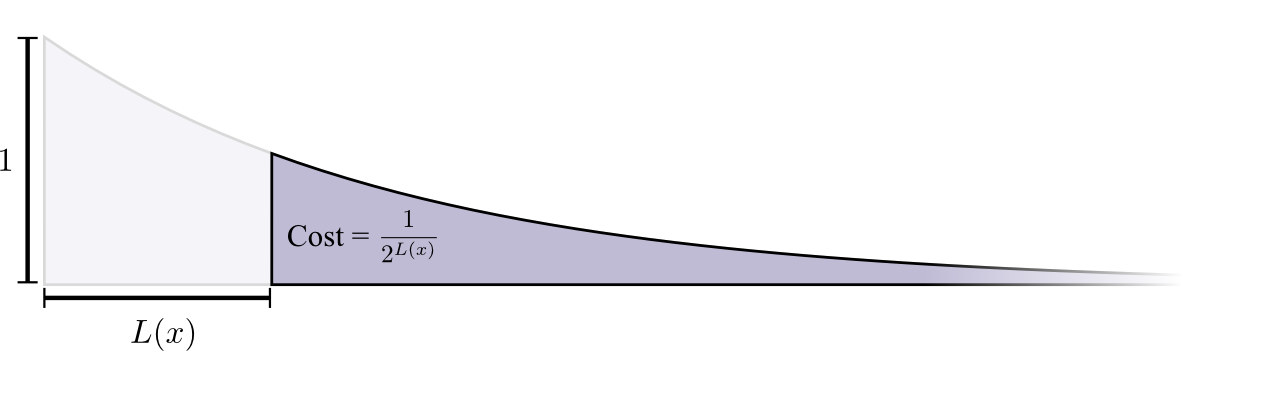
Công thức tính Entropy
Chi phí cho codeword độ dài L là , hay ngược lại nếu ta biết của 1 codeword thì ta có thể tính được độ dài của codeword như sau: . Nếu bạn “tiêu” một chi phí cho codeword , độ dài của codeword x sẽ là .
Với một phân bố xác suất cụ thể , ta xác định được độ dài trung bình ngắn nhất của bộ codeword - được gọi là “entropy” của , kí hiệu là . Ta có:
Nói một cách khác, nếu x là một sự kiện ngẫu nhiên rời rạc (có thể nhận các giá trị là 1..n), là xác suất xảy ra của giá trị x, thì Entropy chính là giá trị kỳ vọng số bits được mã hoá tối ưu. Như vậy, trung bình mỗi khi cần nhắn tin, Bob và Alice cần sử dụng ít nhất bit.
Entropy mô tả độ “không chắc chắn” của thông tin và là một cách để bạn định lượng được thông tin này. Giả sử nếu bạn biết chắc chắn có 2 sự kiện xảy ra với xác suất 50/50, bạn chắc chắn chỉ cần dùng 1 bit để nhắn tin. Hoặc nếu bạn biết có 16 sự kiện xảy ra với xác suất như nhau và thì bạn chắc chắn chỉ cần 4 bit để nhắn tin.
Cross Entropy

Trở lại với câu chuyện của Bob và Alice, lúc trước 2 bạn chỉ nói tới sự quan tâm của Bob về 4 loại động vật: , , và , đặc biệt sở thích của Bob về . Có chút thay đổi trong hoàn cảnh này là với Alice, cô cũng thích cả 4 loại động vật trên như Bob, nhưng cô thích nói về hơn cả. Như vậy, 2 người có cùng “” nhưng khác nhau về tần suất cho từng loại. Bob có thể nói cả ngày về chủ đề , trong khi đó Alice lại cũng có thể nói cả ngày với chủ đề .
Cụ thể như hình dưới đây:
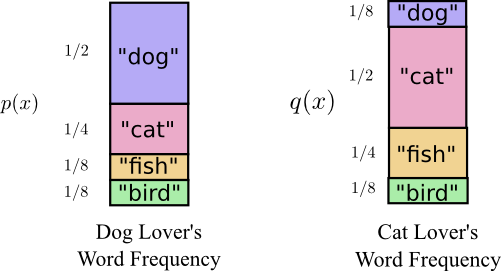
Ban đầu, Alice gửi tin cho Bob cùng sử dụng bộ code của Bob. Tuy nhiên tin nhắn của Alice lại có vẻ dài hơn so với mong đợi của 2 bạn. Bộ code của Bob đã được tối ưu dựa trên phân bố xác suất của Bob. Alice đã sử dụng bộ code được tối ưu (suboptimal) dựa trên phân bố xác suất của riêng mình. Do đó trong khi độ dài trung bình codeword của Bob là sử dụng bộ code của Bob là bit, thì độ dài trung bình codeword của Alice sử dụng bộ code của Bob lại dài hơn là bit.
Vậy làm sao để đánh giá 2 codeword này??
Cross-Entropy là độ đo đánh giá độ dài trung bình số lượng bit cần thiết để mã hoá thông điệp với phân bố xác suất là , sử dụng bộ codeword tối ưu (có phân bố xác suất là ).
Nếu bạn nghĩ phân bố xác suất là một tool để mã hoá thông tin, thì entropy là độ đo để đánh giá số lượng bit bạn cần để sử dụng tool chuẩn - đây là tool đã được tối ưu vì bạn không thể mã hoá sử dụng số bit trung bình ít hơn.
Ngược lại, cross-entropy là số lượng bit bạn cần để nếu bạn mã hoá thông tin của tool chuẩn sử dụng tool sai . Nghĩa là khi mã hoá thông điệp cho sự kiện thay vì sử dụng bit bạn lại dùng bit.
Ta có:
Ví dụ ta có:

- Cross-entroy luôn luôn lớn hơn Entropy; Việc mã hoá sử dụng tool sai sẽ luôn phải sử dụng nhiều bit hơn.
- Cross-entropy không có tính chất đối xứng, nghĩa là .
Ta có thể có một vài kịch bản sau:
- Bob sử dụng Bob code: bit
- Alice sử dụng Bob code: bit
- Alice sử dụng Alice code: bit
- Bod sử dụng Alice code: bit
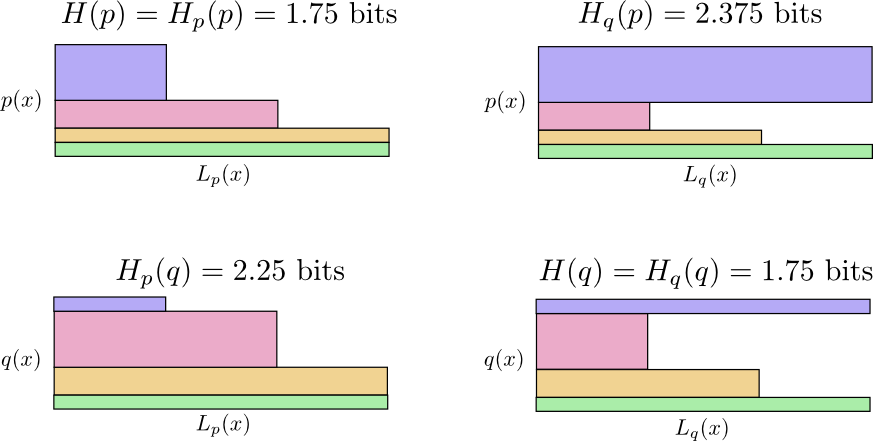
Tại sao cross-entropy lại quan trọng ???
Cross-entropy cho biết sự mức độ khác biệt giữa 2 phân bố xác suất. Sự khác biệt giữa phân bố và càng lớn, thì cross-entropy của p đối với q sẽ càng lớn hơn entropy của p.
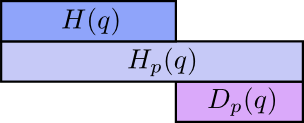
Tương tự, sự khác biệt giữa phân bố và càng lớn, thì cross-entropy của q đối với p sẽ càng lớn hơn entropy của q.
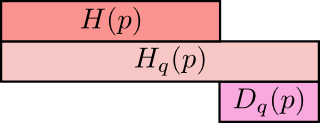
KL Divergence - KL phân kỳ
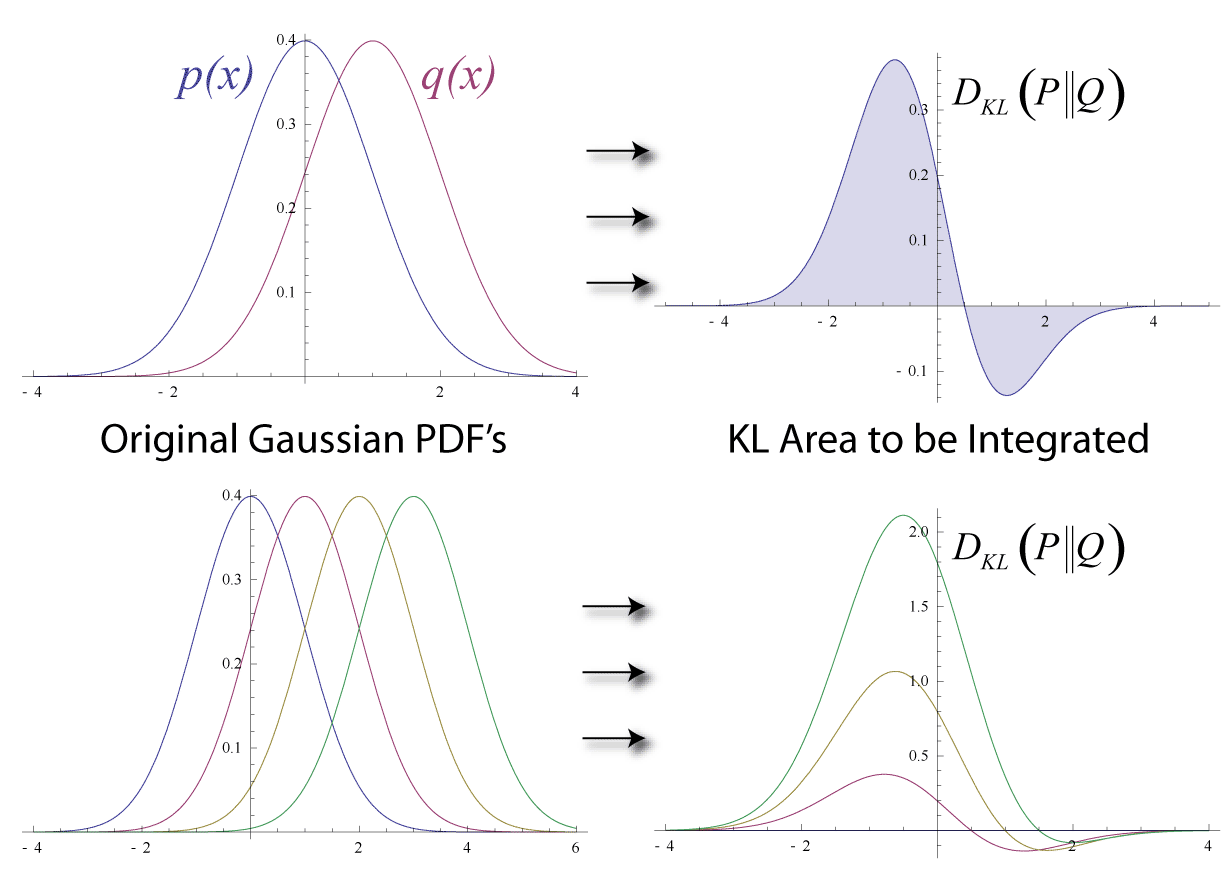
Điều thực sự thú vị ở đây chính là sự khác biệt giữa entropy và cross-entropy. Có thể nói nó là sự khác biệt hay khoảng cách giữa 2 phân bố xác suất và . Nếu 2 phân bố xác suất này giống nhau thì khoảng cách là và ngược lại sự khác biệt càng lớn thì giá trị này càng lớn.
Và nó được gọi là KL divergence:
\begin{equation} D( p | q) = \sum_x p_x \log \frac{1}{q_x} - \sum_x p_x \log \frac{1}{p_x} = \sum_x p_x \log \frac{p_x}{q_x} = H(P, Q) - H(P) \end{equation}
với là cross-entropy; là entropy của P.
Lưu ý:
- Việc cực tiểu hoá cross entroypy tương đương với việc cực tiểu hoá KL phân kỳ.
- Cross entropy và KL phân kỳ được sử dụng phổ biến trong Machine Learning. Chúng ta thường muốn một phân bố xác suất nào đó tiến gần với một phân bố khác. Ví dụ như chúng ta muốn phân bố của dự đoán tiến gần với phân bố cơ sở. KL phân kỳ cho ta một cái nhìn tự nhiên về vấn đề trên, tuy nhiên có vẻ như cross entropy lại được biết đến và sử dụng rộng rãi hơn.
Khả năng dự đoán

Ở đây chúng ta sử dụng cross-entropy để đánh giá sự khác biệt giữa 2 phân bố xác suất và và tính lỗi (loss) dựa trên tổng cross entropy của toàn bộ dữ liệu training.
Cụ thể ta có hàm mục tiêu như sau:
\begin{equation} H({y^{(n)}}, {\hat{y}^{(n)}}) = \sum_n H(y^{(n)}, \hat{y}^{(n)}) \end{equation}
Một cách tiếp cận phổ biến khác là chúng ta tiến hành điều chỉnh tham số mô hình sao cho likelihood của mô hình với dữ liệu đầu vào đạt max. Với bài toán phân lớp chúng ta thường hay sử dụng mô hình phân biệt (discriminative model) ở đó dữ liệu training thường bao gồm cả dữ liệu và nhãn cần dự đoán. Nói cách khác chúng ta thường sẽ dự đoán ground-truth labels với dữ liệu cho trước.
Với giả sử dữ liệu của bài toán là độc lập và phân bố đồng nhất (independent and identically distributed), likelihood sẽ được tính như sau:
Vậy thế nào là likelihood? Đó chính là phần tử cụ thể của tương ứng với ground-truth label của .
Ví dụ trong bài toán phân loại ảnh số MNIST: Với ảnh training thứ nhất có nhãn là , thì likelihood sẽ là phần tử thứ 3-th của kết quả dự đoán , hay .
Tiếp tục giả sử chúng ta có tất cả 3 ảnh trong training data là các số 3, 5, 8 với các phân bố ground-truth là:
,
, và
.
Mô hình sẽ dự đoán 3 phân bố tương ứng là:
,
, và
.
Và likelihood của cả training data sẽ là:
Vậy nhiệm vụ của chúng ta là điều chỉnh tham số mô hình sao cho likelihood đạt max.
Likelihood

Cùng phân tích cụ thể hơn về công thức tính likelihood trên:
Thứ nhất, hàm logarit là hàm đơn điệu, do vậy việc cực đại hoá likelihood sẽ tương đương với việc cực đại hoá log likelihood, hay ngược lại là tương đương với việc cực tiểu hoá negative log likelihood.
Thứ hai, như chúng ta phân tích ở phần trên, log likelihood của được tính khá đơn giản chính là log của phần tử tương ứng trong , cụ thể hơn là phần tử thứ thoả mãn .
Do đó chúng ta có thể viết lại công thức tính log likelihood cho mẫu training data thứ đơn giản hơn như sau:
và negative log likelihood cũng được viết lại như sau:
Và đây chính là công thức tính tổng tất cả cross-entropy trên toàn bộ training data:
Thảo luận

Khi xây dựng mô hình xác suất cho bài toán phân lớp có các lớp phân biệt lẫn nhau, chúng ta cần đánh giá sự khác biệt giữa xác suất dự đoán và xác suất ground-truth và trong quá trình training chúng ta sẽ điều chỉnh tham số sao cho sự khác biệt là nhỏ nhất.
Và các bạn có thể nhận thấy rằng, cross-entropy là một lựa chọn phù hợp cho bài toán phân lớp trên.
Có 2 khía cạnh đánh giá việc tiếp cận này:
- Thứ nhất, việc cực tiểu hoá cross-entropy cho phép chúng ta tìm được thoả mãn đáp ứng số bits tối thiểu cần thiết để mã hoá thông tin từ sử dụng
- Thứ hai, việc cực tiểu hoá cross-entropy tương đương với việc cực tiểu hoá negative log likelihood hay chính là việc đánh giá trực tiếp khả năng dự đoán của mô hình.