Hàm Scan trong Tensorflow
Hàm scan là một một trong những hàm quan trọng trong Theano và giờ đây đã được Tensorflow sử dụng bởi sự tiện lợi và linh hoạt của nó.
Overview
Hàm Scan cho phép bạn sử dụng vòng lặp trong Đồ thị tính toán (computation graph) của Tensorflow, cho phép bạn sử dụng thuật toán lan truyền ngược (backpropagation) và một số kỹ thuật khác trong Machine Learning. Trong Tensorflow bạn có thể định nghĩa k nodes mới cho vòng lặp có k steps. Tuy nhiên giá trị k sẽ cố định thay vì được tuỳ chỉnh mềm dẻo và việc này làm cho đồ thị tính toán của bạn trở nên chậm chạp hơn rất nhiều.
Formular
tf.scan(fn, elems, initializer=None, parallel_iterations=10, back_prop=True, swap_memory=False, name=None)
Toán tử Scan áp dụng lặp đi lặp lại hàm fn trên chuỗi các thành phần elems từ trái sang phải. Các thành phần này được tạo nên từ các tensor được unpack từ elems theo chiều (dimension) 0. Hàm khả gọi fn nhận vào 2 đối số là 2 tensor: Tensor thứ nhất là giá trị tích luỹ được tính từ lời gọi hàm fn tại bước ngay trước. Nếu initializer = None, elems phải chứa ít nhất 1 phần tử và phần tử đầu tiên sẽ được sử dụng như là phần tử khởi tạo initializer.
Giả sử elems được giải nén thành tensor values là list của các tensor, hàm fn sẽ trả về tensor có định dạng shape = [len(values)] + fn(initializer, values[0]).shape
Tham số:
- fn: Hàm áp dụng.
- elems: Tensor có thể unpack theo chiều (dimension) 0.
- initializer: (optional) Giá trị khởi tạo.
- parallel_iterations: (optional) Số bước lặp cho phép chạy song song.
- back_prop: (optional) True cho phép back propagation.
- swap_memory: (optional) True cho phép hoán đổi việc sử dụng GPU-CPU memory.
- name: (optional) Name prefix for the returned tensors.
Kết quả:
Một Tensor được nén các kết quả trung gian áp dụng hàm fn trên list các tensors giải nén từ elems, theo thứ tự từ trái sang phải.
Ví dụ
elems = [1, 2, 3, 4, 5, 6]
sum = scan(lambda a, x: a + x, elems)
#=> sum == [1, 3, 6, 10, 15, 21]
Nào hãy cùng phân tích 2 ví dụ đơn giản để hiểu rõ hơn cách sử dụng Scan trong Tensorflow:
-
Ví dụ 1: Viết một chương trình tính tổng luỹ tích của một list sử dụng scan.
Input : [1, 2, 2, 2]
Output: [1, 3, 5, 7]
-
Ví dụ 2: Sử dụng RNN để giải quyết Ví dụ 1 bằng cách train RNN để dự đoán chuỗi output [1, 3, 5, 7] từ chuỗi input đã biết [1, 2, 2, 2].
Example 1: Hard code
Output: [ 1. 3. 5. 7.]
Ví dụ trên là cách đơn giản để sử dụng Scan. Vậy thực sự Scan làm việc như thế nào trong Tensorflow:
Scan duyệt qua lần lượt từng phần tử trong elems, tại mỗi vị trí k sẽ áp dụng hàm fn với inputs là output của bước trước đó k-1 và input của bước hiện tại. Giá trị tại bước k = 0 được gán khởi tạo trong initializer:
-
Lặp 0: fn(0.0, 1.0) == 1.0
-
Lặp 1: fn(1.0, 2.0) == 3.0
-
Lặp 2: fn(3.0, 2.0) == 5.0
-
Lặp 3: fn(5.0, 2.0) == 7.0
Dòng 6: elems = tf.identity(elems): Sử dụng để fix lỗi ở đây.
- Không sử dụng hàm
tf.identity(): Trong ví dụ trên, ta muốn tính cộng thêm 1 và giá trị của biếnxtạidòng 5sau mỗi lầnyđược kiểm tra để in ra ởdòng 11. Tuy nhiên:
Kết quả là: 0.0, 0.0, 0.0, 0.0, 0.0
Vấn đề được giải quyết bằng cách sử dụng tf.identity() như ở code dưới đây:
- Sử dụng hàm
tf.identity():
Kết quả là: 1.0, 2.0, 3.0, 4.0, 5.0
Example 2: Learning to predict the Sum
Ở ví dụ này, chúng ta sẽ viết một chương trình sử dụng mô hình RNN (Recurrent Neural Network) và huấn luyện (train) mô hình để dự đoán hàm sum từ tập dữ liệu huấn luyện (training data).
Importing libs
Generating Inputs and Targets
Trước hết chúng ta sẽ sinh training data là các cặp chuỗi input và chuỗi target tương ứng (được dùng như là những vector cột shape=[k, 1])
Defining the RNN Model from Scratch
Tiếp theo, định nghĩa RNN model. Code tuy có hơi dài nhưng cơ bản với những comment giải thích bên trong sẽ giúp bạn dễ dàng hiểu và thực hành hơn.
Các thành phần chính của RNN như sau:
- Trạng thái (state) của RNN được update bởi công thức:
- _vanilla_rnn_step là thành phần chính của mô hình RNN này: Nó áp dụng công thức trên bằng việc nhận đầu vào là trạng thái của bước trước cùng với input hiện tại và sinh ra trạng thái mới. Có một chút bối rối ở đây khi các bạn phải xử lý shape của các tensor bằng cách chuyển vị (transpose) sao cho phù hợp với việc tính toán và yêu cầu của Tensorflow.
- _compute_predictions áp dụng _vanilla_rnn_step cho mọi bước sử dụng scan, mỗi bước cho kết quả là một trạng thái mới, sau đó sử dụng một layer để biến shape của trạng thái thành shape của target và dự đoán kết quả.
- _compute_loss tính khoảng cách Euclid trung bình (mean squared Euclidean distance) giữa target thực tế và kết quả dự đoán được.
Defining an Optimizer
Chúng ta tiếp tục định nghĩa lớp Tối ưu hoá (Optimizer). Trong lớp này chúng ta sẽ sử dụng thuật toán gradient descent để update mô hình, sử dụng kỹ thuật cắt ngọn (gradient clipping) để tránh việc bùng nổ gradient (exploding gradient), bằng cách sử dụng ngưỡng max_global_norm - Khi đó tại mỗi bước tính toán gradient, mỗi khi global norm (tổng norm của tất cả gradients) vượt quá ngưỡng sẽ được chuẩn hoá thành max_global_norm.
Training
Mọi thứ đã sẵn sàng, chúng ta tiến hành định nghĩa và thực thi hàm train, tại đây chúng ta sẽ thực hiện các bước tính toán và update tham số của mô hình, và ghi nhận lại thông tin của của mô hình để có thể quan sát một cách trực quan thông qua công cụ TensorBoard của Tensorflow.
Mô hình đươc train như sau:
Sau khi train mô hình, chạy lệnh tensorboard --logdir ./logdir, vào địa chỉ http://localhost:6006 để quan sát các thông số của mô hình: loss, biểu đồ train mô hình qua từng steps, mô hình trực quan, …
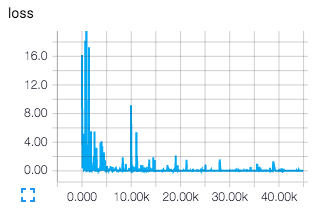
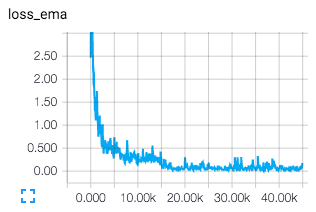
Testing Qualitatively
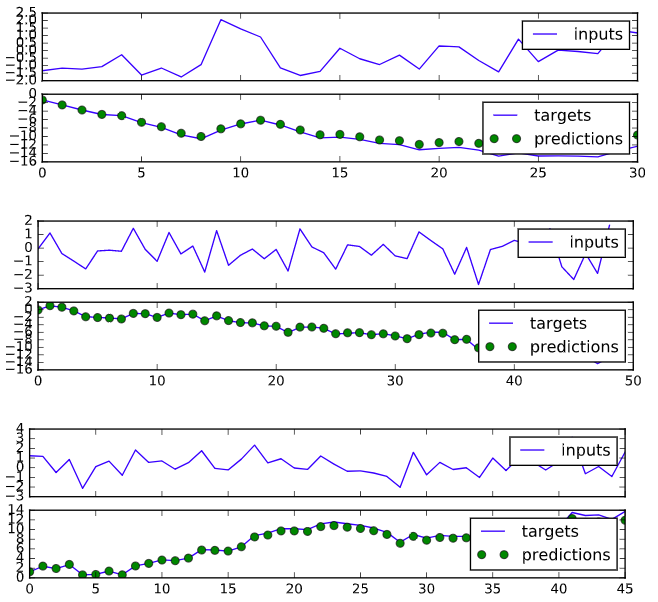
Cuối cùng chúng ta tiến hành kiểm tra chất lượng của mô hình bằng cách vẽ chuỗi target và chuỗi dự đoán trên cùng một biểu đồ, nếu 2 chuỗi có xu hướng chồng lên nhau thì mô hình cơ bản là tốt, ngược lại nếu 2 chuỗi tách biệt nhau thì mô hình dự đoán yếu.
và chạy:
test_qualitatively(sess, model, generator, figsize=(8, 2))
Kết quả như sau:
Discussion
Vậy là các bạn đã hoàn thiện một chương trình RNN đơn giản để huấn luyện mô hình dự đoán chuỗi tổng luỹ tích từ chuỗi input cho trước. Một số phần các bạn có thể lưu ý để cải thiện mô hình tốt hơn:
- Giá trị của
hidden_layer_size, trong mô hình trên chúng ta gánhidden_layer_size = 256. Các bạn hãy thử với các giá trị nhỏ hơn (mỗi lần chia cho 2) và quan sátloss. - Giá trị của
initial_learning_rate=1e-2. Hãy thử với các giá trị khác và quan sátloss. - Giá trị cho gradient clipping
max_global_norm=1.0. Hãy thử train mô hình mà không sử dụng gradient clipping, cùng đó kết hợp với lựa chọninitial_learning_ratephù hợp.
Conclusion
- Mô hình trên được huấn luyện tại mỗi bước cho sử dụng duy nhất 1 cặp chuỗi input và target. Việc này làm tăng thời gian huấn luyện mô hình. Cải thiện bằng cách có thể sử dụng input_size lên tuỳ thuộc vào cấu hình máy.
- Mô hình trên sử dụng chỉ một layer, chúng ta có thể mở rộng thành deep model bằng cách chồng thêm 1, 2, … các layer lên nhau: Thực hiện hàm scan để lấy kết quả layer thứ nhất, chạy scan lần thứ hai để lấy kết quả của layer thứ 2, cứ tiếp tục như vậy. Lưu ý: Output của layer l sẽ là input của layer l+1.
- Mô hình RNN cơ bản này ít khi sử dụng gần đây do hai vấn đề của nó là triệt tiêu và bùng nổ gradient (<a href=”“https://en.wikipedia.org/wiki/Vanishing_gradient_problem>vanishing và expoding gradient</a>). Hai mô hình thay thế cho RNN hay được sử dụng là LSTM (Long-Short Term Memory) và GRU (Gated Recurrent Unit).
- Chúng ta đang sử dụng thuật toán BPTT (backpropagation through time) đầy đủ bằng cách thực hiện toàn bộ quá trình lan truyền xuôi, ngược cho mỗi lượt update gradietn. Việc này làm cho quá trình train mô hình của chúng ta trở nên chậm, tốn thời gian. Một kỹ thuật thay thế là sử dụng truncated backpropagation through time bằng cách cập nhật thông tin của mô hình thông qua một khoảng thời gian gần hơn trong quá khứ tuy vậy vẫn đảm bảo giữ được thông tin xa hơn quá khứ vì chúng cũng được lưu lại trong các trạng thái.